Autor: Carlos Rodrigues em 7/12/2013
Intrudução
A área de TI hoje em dia não é mais apenas um departamento técnico, ou provedor de tecnologia, a TI desempenha com grande importância um papel fundamental para o negócio das empresas, buscando otimizar os seus processos internos, reduzindo custos e riscos inerentes à atividade em si, da empresa.
Deste modo, a área de TI, para satisfazer uma necessidade crescente dos mercados de negócio e seus diversos “players” e clientes, rasga com a tradicional ideia que é apenas tecnologia, para fornecer respostas apoiadas nas necessidades dos clientes de forma a apresentar um serviço de qualidade tolerante a falhas e resiliente.
Segundo um estudo realizado pelo instituto Gartner, as causas de indisponibilidade provenientes em uma empresa derivaram da tecnologia em 20%, sendo os restantes 80% atribuidos aos processos e pessoas, sendo 20% para software, 15% para questões relacionadas com rede, 10% para o fator de erro humano, 5% para aspectos de segurança e 30% para causas desconhecidas.
Neste artigo pretendemos abordar os aspetos do ITIL no que respeita ao Plano de continuidade de negócio (PCN)- Backup e restauração, com os aspetos de segurança da informação - riscos, ameaças e vulnerabilidades, alinhados com o negócio produzido nas empresas que trabalham com tecnologia da informação.
A TI é um conjunto de atividades e soluções providas por recursos de computação ligadas as mais diversas áreas e aplicações. Esse conceito é mais abrangente do que se imagina, pois envolve aspectos humanos, administrativos e organizacionais, não se restringindo apenas em hardwares e softwares ou a comunicação de dados, mas abrangendo também planejamento, suporte e desenvolvimento. “A tecnologia da informação pode ser considerada como recursos tecnológicos e computacionais para a guarda, geração e uso da informação e do conhecimento.”
(REZENDE, 2003)
ITIL - INFORMATION TECHNOLOGY INFRASTRUCTURE LIBRARY
Definição
ITIL (Information Technology Infrastructure Library), segundo o site oficial é a abordagem mais amplamente aceita para gerenciamento de serviços de TI no mundo. O ITIL fornece um conjunto coeso de melhores práticas, retiradas dos setores público e privado a nível internacional.
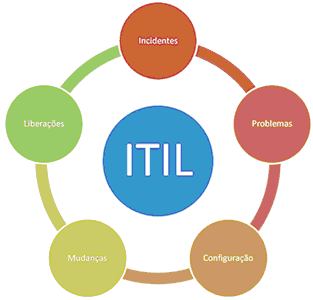
Figura 1.1 – Gráfico com as várias fases do ITIL
No final dos anos 80, a CCTA (Central computer and telecommunication Agency) na Inglaterra fornecia suporte governamental na área de informática e telecomunicações, já atualmente quem detém a custódia do ITIL é a OGC (Office for Government Commerce) também na inglaterra, porém com uma vertente tanto pública quando privada que busca direcionar a gestão de uma empresa auxiliada pelas tecnologias da informação ao cliente final, ou seja ao usuário e não à empresa em si só, isto faz com que o alinhamento do negócio vá de encontro às necessidades e expectativas dos clientes, produzindo como resultante uma TI com maior qualidade que apoia as estruturas das empresas e atende aos processos de administração e gestão de uma organização de uma forma melhorada e otimizada.
A ITIL surgiu como reconhecimento do fato de que as organizações estão se tornando cada vez mais dependentes da TI para atingir seus objetivos corporativos. Essa crescente dependência resultou numa necessidade cada vez maior de serviços de TI com uma qualidade que corresponda aos objetivos do negócio e que atendam às exigências e expectativas do cliente.
(VAN BON, 2006)
A ITIL na sua primeira versão 1.0 que remonta ao ano de 1991 é composta por quarenta livros, devido a este fato o termo “biblioteca” foi adotado para nomear este modelo.
A versão 2.0, lançada em 2000, foi reformulada reunindo sete melhores práticas, que são:
- Entrega de Serviço;
- Gerenciamento da Infra-Estrutura de TI e de Comunicação;
- Gerenciamento da Segurança;
- Gerenciamento de Aplicações;
- Gerenciamento dos Ativos de Software;
- Perspectiva do Negócio;
- Planejamento e Implementação e Suporte ao Serviço.
Em 2007 foi finalmente lançada a versão 3.0 que reune o melhor do ITIL em cinco livros nos quais apresenta o conceito de gerenciamento de ciclo de vida do serviço, composto pela:
- Estratégia de Serviço;
- Desenho de Serviço;
- Transição de Serviço
- Operação de Serviço
- Melhoria Contínua nos Serviços.
ITIL é uma estrutura, um conjunto de diretrizes de práticas recomendadas que visa ajustar pessoas, processos e tecnologia para aumentar a eficiência do gerenciamento de serviços. Não é uma doutrina ou um padrão rígido, na medida em que algumas vezes pode ser interpretada. Embora forneça orientação para um conjunto comum de práticas recomendadas, cada implementação de ITIL é diferente e pode mudar de acordo com as necessidades da organização. (apud, OGC, 2003)
Como podemos verificar aqui pela tradução supra, a ITIL é sem dúvida muito mais que uma série de livros apresentando as melhores práticas em gerência de recursos de TI. Podemos considerar a ITIL como uma “framework”, uma ferramenta que visa ajudar a atingir os objetivos das empresas que por serem amplamente usados no mercado empresarial, foram testados e comprovados que resultam na melhoria dos serviços e processos a serem usados, poupando a perda de tempo e recursos das empresas.
BCP - PLANO DE CONTINUIDADE DE NEGÓCIO
Definição
Plano de continuidade de negócio, proveniente do termo em inglês BCP (Business Continuity Plan), pode-se entender como o processo de implementação de politícas, control e procedimentos que mitigam os efeitos de perda, avarias e falhas críticas a continuidade dos negócios de uma forma normal e estável. Neste artigo vamos utilizar o termo em inglês BCP em vez do PCN por uma questão de maior facilidade na exposição dos conceitos.
O BCP, também chamado por alguns autores de plano de contigência, asseguram que no caso de uma CBF (Critical Business Function) deixar de operar segundo os critérios estabelecidos durante o planeamento do processo de continuidade, este entra em ação e assegura deste modo a reposição daquele serviço, ou processo que foi afetado de alguma forma, seja por algum fator humano, ou externo a este, como por exemplo as causas de desastres naturais, impossíveis de prever.
CBF (Critical Business Function), do inglês, função crítica de negócio, refere-se aos processos ou sistemas que têm a necessidade imediata de serem restabelecidos após uma falha ter acontecido, pois compreeende-se que o negócio em causa não pode prosseguir sem eles, por desempenharem um fator crítico nas organizações, também chamados de missão crítica.
O plano de continuidade de negócios é de inteira responsabilidade dos altos cargos de gestão de uma organização e o que se espera da TI é apenas auxíliar nesta tarefa, não podendo ser repassado para o departamento de TI a responsabilidadade de sua implementação ou não.
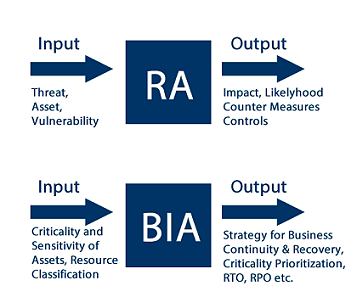
Figura 1.2 – Gráfico que demonstra os 2 componentes de um BCP
Componentes do BCP
Na imagem acima podemos verificar dois componentes bastante importantes que formam o BCP, o RA do inglês (Risk Analysis), ou análise de riscos que é o entendimento da probabilidade de um desastre ou de uma interrupção no serviço vir a acontecer e o BIA, do inglês (Business Impact Analysis), que é o processo que avalia os cenários de impactos.
Ambos estão intrinsecamente ligados para o mesmo fim, traçar um BCP que avalie todos os processos dentro de uma organização ou empresa, necessários para um plano de contigência ser efetivo em caso de uma emergência ocorrer.
2.1.3 Risco, Ameaça e Vulnerabilidade
Antes de se iniciar a discução sobre os 2 compoentes que formam um plano de continuidade, vamos analisar o sentido dos termos risco, ameaça ou vulnerabilidade.
Risco, entende-se que é um evento ou condição que pode acontecer, que irá gerar um efeito, proveniente de uma determinada ação que pode ter um impacto negativo ou positivo na organização ou empresa.
Já a ameaça é um ambiente ou situação propício para a fuga ou abertura de uma potencial brecha a nível de segurança que pode ser protagonizada por uma pessoa ou ferramenta, que pretende tirar vantagem de uma vulnerabilidade que foi descoberta ou analisada.
A vulnerabilidade em si é em grande parte uma debilidade, fraqueza ou defeito de um sistema de protecção, de uma rede, computador ou software, mas também pode ser uma falha de um design lógico, do inglês “logic design ”, ou erro de implementação, do inglês “error implementation”.
Quando uma vulnerabilidade existe em um sistema, uma ameaça pode tomar conta deste fato e tentar tirar vantagem, explorando a falha descoberta executando ferramentas vulgarmente chamadas de “Attack tools”, para tal é necessário tomar as contra-medidas necessárias para minimizar uma possível situação de desastre que possa vir a se verificar, proveniente desta ação ilícita.
2.1.4 RA – Risk Analysis
A avaliação de riscos identifica as probabilidade de um risco poder vir a ocorrer, avalia esse risco e o impacto para a organização ou empresa, no caso de um determinado sistema ou serviço deixar de funcionar. Claro que sem esta prévia analise é impossível primeiro, conhecer quais são os riscos com que a organização tem que lidar; segundo, quais as alterações e tomadas de decisão que a política de segurança da empresa tem que endereçar para cumprir com as necessidades da alta administração da empresa.
Figura 1.3 – Desenho ilustrativo do fator risco associado ao investimento
Seguindo a ideia de “você não sabe o que proteger, se não souber o que tem”, deste modo é necessário fazer um inventário para identificar quais são as missões críticas na empresa, serviços em particular ou processos que podem estar em risco, conhecer os níveis de ameaças e vulnerabilidades.
Quando o inventário estiver finalizado, os riscos podem ser prioritizados, seguindo a lógica decrescente dos mais graves para os menos graves, deste modo vai conseguir endereçar todos correndo o menor risco possível se algum falhar e fechar a produção de uma empresa.
O Objetivo de uma avaliação e análise de riscos é ter o conhecimento necessário para poder mitigar o mesmo, transferir se for necessário essa responsabilidade para outrém, por exemplo uma seguradora, aceitar uma potencial perda, sendo que neste caso este serviço ou processo não seria considerado pelo ITIL como uma boa prática, pois se não tem interesse, porque existe em primeiro lugar, ou ignorado, sendo que é considerado inaceitável esta posição pois negar que o risco existe ou não é válido, esperando que nunca venha a acontecer é um dos fatores de maior perigo dentro de uma organização, pois se uma empresa não está prevenida para suportar os encargos de um risco que foi ignorado, ao acontecer fica completamente vulnerável ao que essa situação pode acarretar para a gestão da empresa.
2.1.5 BIA – Business Impact Analysis
Análise de impacto nos negócios é o processo de realizar avaliações de risco em tarefas e processos nos negócios, em vez dos bens ativos da empresa.
Figura 1.4 – CRAMM (CCTA Risk Analysis and Management Method)
O objectivo do BIA é manter o correto funcionamento do negócio, com o BCP, ele se propõe a encontrar os riscos no negócio em processos e apresentar soluções de defesa e de recuperação.
O BIA avalia a probabilidade de uma ameaça vir realmente a acontecer e a demonstrar o impacto que iria ter no negócio, avaliando cenários de impacto e determinando efeitos de indisponibilidade de serviço.
Esta análise também avalia quanto tempo uma empresa poderia esperar ou aguentar até um serviço de missão critica ser restabelecido, avalia os requesitos minímos que seriam necessários para manter os processos criticos para o negócio, determina os tempos minimos e máximos para os serviços serem recuperados e quais os processos de negócio que devem ser recuperados por completo.
Toda esta avaliação é quantitativa, o que ajuda uma empresa a prioritizar o seu comprometimento com os vários riscos que uma organização pode enfrentar.
2.1.6 NORMA ABNT NBR 15999
Originalmente criada pela BSI (British Standards Institution) em 2006, a norma britânica BS 25999 foi publicada no Brasil em outubro de 2007 pela ABNT com o nome ABNT NBR 15999, ela constitui a primeira norma existente que visa os interesses de continuidade de negócios em uma empresa, do inglês, BCM (Business Continuity Management).
Já a norma ABNT NBR 15999-2, originária da BS 25999-2, especifica os requisitos de um plano para manter em funcionamento uma empresa ou organização em caso de alguma ocorrência grave vir a acontecer.
Tem como objetivo principal garantir os processos para que uma empresa retorne ao seu estado de normal funcionamento após ter passado por um determinado incidente, sendo que o seu propósito é sempre minimizar os prejuízos.
DRP - PLANO DE RECUPERAÇÃO DE DESASTRE
Definição
DRP (Disaster Recovery Plan), é essencial à gestão de uma empresa, pois pode-se considerar como uma expansão do plano de continuidade BCP. Podemos entender que o DRP na sua generalidade, como a possibilidade de uma empresa recuperar o seu funcionamento totalmente ou parcialmente após um evento de desastre, que se tenha verificado em uma determinada altura.
Planear um plano de desastre é algo complexo e que ocupa bastante tempo administrativo até se conseguir um resultado satisfatório, tem que se perceber que o DRP só entra em ação quando o BCP falhou e não consegue de nenhuma forma continuar o negócio, pois as missões críticas foram afetadas de tal forma que só uma recuperação servirá aos propósitos de uma empresa.
Issto acontece normalmente quando o local principal de uma empresa é afetado e fica impedido de garantir as funcionalidades primárias do negócio, neste momento o DRP passa a seu estado de ativo.
Devido aos negócios hoje em dia serem muito dinâmicos e estarem em constante mudança, em parte devido aos avanços sistemáticos das tecnologias, o desenvolvimento de um plano de DRP tem que sofrer várias alterações de tempos em tempos, de forma a ser ajustado à realidade das empresas.
Um fator aqui importante é que todas as antigas cópias de planos que foram modificadas devem ser destruídas, sendo que apenas o mais recente plano de desastre deve existir, de forma que não exista nenhum desvio ou lapso na execução do mesmo .

Figura 1.5 – Imagem ilustrativa de perguntas na elaboração de um DRP
Extraído do site carlosrodrigues.it
É também necessário serem executados ou conduzidos, depois do desenvolvimento finalizado, exercícios e simulações de desastres, de forma a analisar possíveis desvios ao plano original, proporcionar treino e conhecimento neste tipo de ambiente hostil e ainda registar comportamentos adversos que uma situação de emergência produz no ser humano.
3.1.2 Backup e backout
O Backup é um aspecto muito importante que deve ser seguido com rigor e que faz parte das melhores práticas do ITIL, em planos de continuidade de negócio, pois é ele que vai garantir e salvaguarda que documentos seram restabelecidos após alguma perda ou inconsistência verificada.
No caso de uma organização ou empresa passar por um episódio de perda de dados, apagamento dos dados por acidente, corrupção dos dados, destruição, intrusão, infecção por algum malware ou desastre, consegue através das cópias de segurança repor os dados afetados, sendo que um backup só pode ser considerado como um “bom backup” se o mesmo tiver sido testado e garantir que as informações estão prontas a serem usadas e em excelente condições.
Se o backup nunca tiver sido testado previamente, é impossível ter a certeza que na altura do desastre o restauro dos dados vai funcionar corretamente e sem nenhuma deficiência.
Existem 3 formas de backup essenciais que devem ser realizados, que passam a ser explicados de forma reduzida.
Backup total, do inglês “full backup”; ele é responsável por realizar cópia integral de todos os dados, apagando ou resetando o atributo “A”, chamado de “archive bit” dos ficheiros que foram submetidos a este tipo de backup.
Backup Incremental, do inglês “Incremental backup”; ele é responsável por realizar cópia apenas dos dados que tenham o atributo “A” nas suas propriedades, isto acontece quando um arquivo foi modificado após um backup total ou incremental. Ou constitui um arquivo novo, criado após o backup total. Este tipo de backup apaga ou reseta o atributo “A”, chamado de “archive bit”.
Backup diferencial, do inglês “differential backup”; ele é responsávei por realizar um backup dos arquivos que foram alterados desde que foi feito um backup completo. Ele não altera ou reseta o atributo “A”, chamado de “archive bit”.
Como melhor prática, o Backup deve ser guardado “offsite”, em um local que não o principal onde a empresa funciona, para prevenir que os dados não se percam no caso de uma catástrofe acontecer.
Para se ter a certeza que os backups não tenham alteração e são constituidos genuinos, devem ser tomadas precauções, no seu transporte e no local físico onde serão cuidadosamente guardados, como por exemplo cofres, ou locais de dificil acesso a pessoas não autorizadas.
No caso de serem dados confidenciais, pode-se ainda adicionar aos mesmos uma “hash” de forma a marcar aqueles dados com uma identificação única impossível de ser alterada e permanecer com a mesma sequência numérica lógica. Os algoritmos mais utilizados e conhecidos são por exemplo o MD5 ou o SHA1, embora já se tenha verificado a existência de alguns ataques bem sucessedidos a estes dois algoritmos, derivado a este acontecimento é necessário utilizar uma sequência de bits mais elevada que o tradicionalmente utilizado, como 256 ou 512 bits.
Se o backup não for de todo possível de ser restaurado o backout, entende-se como a possibilidade de reverter um sistema ao seu estado inicial, antes do ponto que sofreu alguma modificação ou alteração. Claro que o backup é essencial, mas em casos em que se verifica a instalação de um “update”, “patch” ou “hotfix” é importante que um plano de backout esteja previsto, pois sem ele uma estrutura pode ficar parcialmente comprometida, criando um impacto negativo nos serviços e processos que podem ser de missão crítica.
A migração de um sistema, ou a instalação de um “firmware” por mais simples que seja pode impactar toda uma estrutura de TI. Contudo é necessário na elaboração de um plano de contigência verificar os contratos e implicações no caso de reverter um sistema, pois este modelo de operação pode não estar contemplado e ter causas financeiras ou legais sobre o negócio de uma organização ou empresa.
3.1.3 Redundancy e Fault Tolerance
Neste ponto vamos analisar os efeitos de redundância e tolerância a falhas, dois componentes que devem sempre existir em um plano de BCP, pois em parte são eles que garante em primeira instância que o negócio prossiga com respostas satisfatórias para os clientes finais. Sendo assim, redundância é a implementação de uma segunda alternativa no caso da primeira deixar de funcionar.
A redundância consegue eliminar o fator de único ponto de falha, do inglês “single point of failure” e por outro lado responder ao problema de sistema não tolerante a falhas. É evidente que um sistema que não seja redundante está suscetível a parar de funcionar por algum problema que se verifique, criando o chamado “downtime” em uma organização ou empresa, este tempo em que o sistema está parado e não consegue produzir vai ser analisado no ponto 3.1.5 deste artigo.
Podemos verificar na foto abaixo, figura 1.6 que além de termos sistemas de “clustering” que garantem a resposta em tempo real no caso de um sistema a nível de “hardware” falhar, ainda foi previsto espalhamento de discos rígidos (hd1, hd2), duplo “link” de internet e por último redundância de sitios onde a organização opera, pois no caso de um deles ser afetado por uma catástrofe o outro local assume as funcionalidade da empresa, eliminando o problema do único ponto de falha.
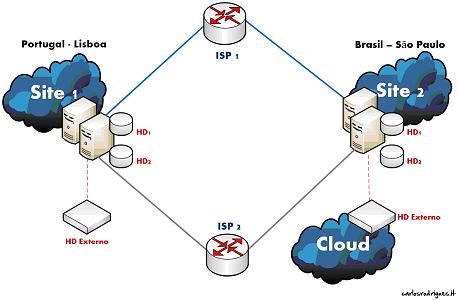
Figura 1.6 – Principais componentes de um sistema de redundância e tolerante a falhas
Extraído do site carlosrodrigues.it
Importante também verificar nesta imagem que os dados de uma empresa devem ser salvaguardados como já referenciado “offsite”, pois só desta forma se consegue garantir que os mesmos se encontram integros e que não sofreram nenhuma modificação, estando livres de qualquer adulteração ou vírus.
Ainda em relação ao “offsite”, vemos que no caso da empresa em questão existe a utilização de um local na nuvem, do inglês “cloud”, que se por um lado cria mais um fator diferenciador no que se refere ao aspecto de redundância, cria aqui um aspecto adicional ainda não descrimindo de disponibilidade de acesso aos dados, pois no caso de o “site1” ser comprometido de alguma forma, assim como o HD externo que é guardado fora das instalações em lugar seguro, também ser comprometido, podemos inserir de uma forma mais rápida os dados de um terceiro local, provenientes da “cloud”, isto porque esta nova tecnologia de armazenamento permite precisamente ter acesso direto aos dados em qualquer lugar do mundo e em qualquer altura (24x7).
Entenda-se que o HD externo no site2 é um espaço na nuvem que foi contratado por alguma empresa da especialidade para armazenar dados, sendo que os planos de BCP ou DRP têm que analisar os SLA´s (Service-Level Agreement´s), que são os contratos legais acordados, afim de identificarem se estes vão suprimir as suas expectativas no caso de um desastre ocorrer.
3.1.4 Hot site, Warm site, Cold site
Outro aspecto importante que um plano de desastre necessita de avaliar é a possibilidade de adquirir um outro local que pode ser permanente ou não, que vai funcionar como um local alternativo, no caso de desastre que impossibilite a continuação do negócio. Os conceitos de “Hot site”, “Warm site” e “Cold site” são os locais destinados para a organização ou empresa poder operar até que o local primário seja restabelecido.
Importante também notar que este tipo de local é provido na sua maior parte das vezes de infraestrutura de escritórios de forma a um número relativamente pequeno de colaboradores consiguir manter o negócio em funcionamento, até a fase final do DRP.
Entende-se assim que um “Hot Site”, também conhecido pelo ITIL como “Hot Standby” é um local que permite recuperação imediata das atividades de uma organização ou empresa, num espaço máximo de 0-24h. É um local já equipado com sistemas de TI (servidores, rede, conectividade, telecomunicações), que permite que as base de dados estejam atualizadas e prontas a serem utilizadas, é normalmente um local dispendioso de se manter pois ele funciona como um local redundante ou secundário ao principal. Toda esta estrutura o ITIL compreende que pode ser de capital próprio ou terceirizado, baixando consideravelmente os custos no caso de ser suportado por outra empresa.
Um “Warm site” , também conhecido pelo ITIL como “Warm Standby” é um local que possui algumas das capacidade de um “Hot site”, em que os tempos de reposição estão entre 24-72h, em parte porque o ambiente já está preparado para funcionamento, mas os bancos de dados são inexistentes, sendo esta uma das principais diferenças, outra seria uma plataforma móvel, ou seja um veículo com uma estrutura de TI que apenas precisa de base de dados para funcionar e gerador após a carga inicial de baterias se terem esgotado.
Por último, temos o “Cold Site”, ou “Cold Standby” vulgarmente conhecida pelo ITIL, dos 3 locais este é o mais desprovido de infraestutura de TI e onde os tempos de espera são os mais longos, sendo superiores a 72h. Este tipo de ambiente permite um local para as operações se iniciarem, mas não suporta infraestrutura para as operações começarem. É um local ideal quando os problemas são antecipados com bastante antecedências, mas é o pior de todos quando se refere a disponibilizar a continuidade de negócios face à demanda dos clientes.
Por outro lado é o menos dispendioso e honoroso de se manter, mas em contrapartida é o que necessita de mais planeamento antecipado, para se levar a cabo um plano de desastre eficaz, por isso é necessário a alta administração da empresa avaliar vários fatores de negócio, antes de optar por uma das soluções aqui apresentadas.
3.1.5 MTTR, MTBF, MTTF
Três outros aspectos que necessitam ser avaliados e que são transversais para um BCP ou DRP ter sucesso em sua execução, são os conceitos de MTTR (Mean time to repair), MTBF (Mean time between failure) e MTTF (Mean time to failure).
Estes três itens estão muito ligados ao conceito de tempo útil que uma determinada máquina, equipamento ou peça de hardware tem e está previsto pelo seu fabricante.
Mas antes de passarmos às dissertações, vamos avaliar o que cada um destes termos significa e entender melhor a sua importancia para o negócio.
MTTR (Mean time to repair) é um termo utilizado para indicar o tempo médio que um equipamento deve ter para ser reparado, sendo que um equipamento pode ser reparado inúmeras vezes até que seja expectável que uma falha ocorra de modo que não seja mais possível ser reparado. Normalmente como se trata de uma peça de “hardware” é importante considerar que pode levar imenso tempo até estar reparado, neste caso o “downtime” provocado pode justificar que a empresa adquira uma nova peça de substituição, para suprimir os tempos de espera. Pode-se também verificar este exemplo prático, caso se trate de um equipamento de missão crítica, onde a redundância pode ter sido um aspecto não considerado no planeamento estrátegico.
MTBF (Mean time between failure) é o tempo esperado ou estimado que antecipa um incidente de falha sobre um sistema ou componente, esta estimativa determina o tempo máximo entre falhas de um componente. O MTBF é mais importante para as industrias e fabricantes do que propriamente para os consumidores, pois conseguem desta forma medir a qualidade do produto que estão a criar, no entanto um departamento de avaliação de riscos, onde um plano de BCP está a ser conduzido estas informações devem ser solicitadas à marca ou representante do produto em questão.
As empresas devem prevenir este tipo de acontecimento e estar preparadas para uma substituição integral do componente, ou reconstrução.
MTTF (Mean time to failure), é uma medida básica de confiança que deve ser utilizada para medir a expectativa da primeira falha do equipamento. Este valor é estatístico podendo ser considerado uma previsão para um evento acontecer e deve ser usado apenas como referência para um possível reparação de um equipamento ou componente.
Como exemplo podemos referenciar a instalação de um determinado “switch” em uma sala de telecomunicações desprovido de “patch panel”, onde as ligações às portas “ethernet” vão ter bastante utilização, neste caso as portas iram suportar um limite de ligações físicas, até que a porta deixe de funcionar totalmente, os fabricantes estimam estes valores que variam de marca para marca.
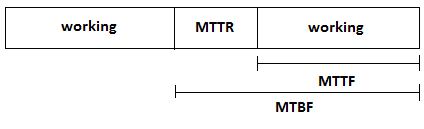
Figura 1.7 – Termos de confiança com linha do tempo demonstrativo
No figura 1.6 supra, podemos verificar que a disponibilidade de um componente ou equipamento é a razão entre o MTTF sobre o MTBF, sendo que o periodo MTBF é o maior de todos, pois entre uma falha e outra a peça ou equipamento em questão pode ser reparada ou mesmo falhar.
Se levarmos em consideração todos 3 conceitos, compreeende-se que uma organização ou empresa necessita em seus planos de BCP criar uma agenda onde permita marcar as tarefas de reparação, reconstrução ou substituição de todos os seus equipamentos.
3.1.6 RTO, MTD
RTO (Recovery Time Objective), é a quantidade de tempo estimado que garanta a recuperação de uma determinada função em caso de desastre. Por outras palavras é o tempo máximo que um processo ou serviço pode ficar sem funcionar, sendo as suas consequências consideradas aceitáveis para o negócio.
Se o tempo de RTO for ultrapassado o mesmo vai provocar um impacto negativo ao negócio e o BCP avalia esta situação como prejudicial, uma vez que os tempos a serem ultrapassados não garantem a continuidade do negócio.
Caso o valor de RTO não seja cumprido, pode-se dizer que o MTD (Maximum tolerable downtime), do inglês tempo máximo tolerável de não funcionamento, não alcançou os seus objectivos e que estavam previstos no BCP e DRP, pois fornece a estes dois planos valores bastante importantes para o funcionamento de uma organização ou empresa.
Este valor varia bastante de empresa para empresa e na prática relata o tempo máximo que um negócio tem após um desastre ter acontecido, para recuperar o seu normal funcionamento de operações sem prejudicar o negócio um todo.
CONCLUSÃO OU CONSIDERAÇÕES FINAIS
O ITIL se apresenta como as melhores práticas que devem ser implementadas numa organização ou empresa que visam o seu melhor funcionamento, claro que cada negócio tem os seus requisitos e características, mas de uma forma geral ela se adapta sempre a qualquer tipo de volume de negócio, seja uma pequena, média ou grande empresa e é precisamente por este interessante fator que ela tem sido bastante disseminada pelo mundo a fora, sem que venha a mostrar algum tipo de falha na sua abordagem dos serviços e processos envolventes.
Por outro lado, também foi visto que os departamentos de TI cada vez mais têm um papel preponderante no sucesso de uma organização ou empresa e sem um devido escrutínio de todas as suas responsabilidades versus melhoramentos, um negócio pode perder “performance” competitiva, por sua vez esta “performance” pode ser alcançada com treinamento de pessoal de TI e esclarecimentos na vertente de segurança no local de trabalho e boas práticas como também foi referido ao longo do artigo.
Sem dúvida que o aspecto de segurança seja física ou lógica é algo que não pode ser desconsiderado pelas organizações e por este mesmo motivo, quando são traçados os objectivos de um BCP em que se vai analisar os riscos, do inglês RA (risk analysis), características como risco, ameaça ou vulnerabilidade que são termos de resto mais aplicados a nível de segurança da informação, são extremamente necessários de serem compreendidos e levados em linha de conta, se pretendemos em última instância que o negócio seja sempre contínuo e não tenha um único ponto de falha ou de vulnerabilidade.
Foi possível também esclarecer que os aspectos de BCP e DRP estão intimamente ligados por um lado à área de negócio e por outro à área de segurança, podendo ser concluído que ambos andam de mãos dadas de forma figurativa, pois sem um o outro não consegue almejar o pretendido e vice versa.
Referências
MAGALHÃES, I. L.; PINHEIROS, W. B.. Gerenciamento de Serviços de TI na prática: uma abordagem com base na ITIL: inclui ISO/IEC 20.000 e IT Flex. São Paulo: Novatec Editora. 2007.
OGC, Office of Government Commerce. Disponível em: < www.itil-officialsite.com > Acesso em 01 de nov. 2013.
OGC, Office of Government Commerce. IT Infrastructure Library ITIL: the key to managing IT services. 2007. Disponível em : < www.itil.co.uk>. Acesso em 02 de nov. 2013.
STEWART, James Michael CompTIA Security+: Review Guide, 2. ed., 101-106 USA: Sybex Wiley, 2011.
DULANEY, Emmett CompTIA Security+: Study Guide, 5. ed., 455-490 USA: Sybex Wiley, 2011.
REZENDE, D. A., Planejamento de Sistemas de Informação e Informática: guia prático para planejar a tecnologia da informação integrada ao planejamento estratégico das organizações. São Paulo : Atlas, 2003.
VAN BON, J. Foundations of IT Service Management, based on ITIL. Lunteren - Holanda: Van Haren Publishing, 2006.
GRAVES, Kimberly CEH: Official Certified Ethical Hacker, Review Guide 1. ed., 2-10 USA: Sybex Wiley, 2007.
|