|
O
projeto bem sucedido de uma rede de computadores pode
ser representado pela capacidade desta em oferecer os
serviços essenciais requeridos por seus usuários e por
preservar os seus principais componentes na eventual
ocorrência de falhas.
A fim de prevenir eventuais
falhas e oferecer alternativas que evitem que estas
acarretem maiores prejuízos, se faz necessário que os
projetos contemplem planos de redund�ncia e contingência
constituídos por uma série de ações e procedimentos
que visam soluções e dispositivos de recuperação relacionados
com essas falhas.
Falhas de Sistema
No ambiente das
redes de computadores podemos destacar vários aspectos
críticos que podem ser considerados pontos de falhas
potenciais para o sistema: cabeamento, servidores, subsistemas
de disco, entre outros. Nesse contexto, as falhas são
consideradas como eventos danosos, provocados por deficiências
no sistema ou em um dos elementos internos dos quais
o sistema dependa.
As falhas podem ser
derivadas de erros no projeto do software, degradação
do hardware, erros humanos ou dados corrompidos. Entretanto,
só existem duas variáveis para a paralisação temporária
de uma rede em função de condições de falha que não
se podem definir ou prever:
Indisponibilidade
� Corresponde ao período de inatividade ou "downtime"
da rede (programado ou não). As características
do projeto devem ser suficientes para garantir que
a informação seja replicada automaticamente do ambiente
de produção para o ambiente de contingência, de
forma que o tempo de indisponibilidade do sistema
seja reduzido, melhorando o nível de serviço e atendendo
às exigências dos usuários;
Instabilidade
- é imprescindível conhecer quais são os par�metros
considerados como normais dentro do ambiente. A
correta definição de métricas de qualidade, bem
como a implantação de mecanismos de coleta e controle
de variáveis do sistema são imprescindíveis para
a configuração de ações de correção imediatas e
de análises de tendências.
Redund�ncia
O termo redund�ncia
descreve a capacidade de um sistema em superar a falha
de um de seus componentes através do uso de recursos
redundantes, ou seja, um sistema redundante possui um
segundo dispositivo que está imediatamente disponível
para uso quando da falha do dispositivo primário do
sistema.
Uma rede de computadores
redundante caracteriza-se, pois, por possuir componentes
como sistemas de ventilação e ar condicionado, sistemas
operacionais, unidades de disco rígido, servidores de
rede, links de comunicação e outros, instalados para
atuarem como backups das fontes primárias no caso delas
falharem.
Essa redund�ncia está
presente, por exemplo, nos sistemas embarcados de aviação,
quando impõe que aviões comerciais possuam dois computadores
de bordo, dois sistemas para controle dos trens de aterrissagem,
etc. Se um sistema falhar, deve ser o outro sistema
tão eficiente e operacional como o primeiro, pronto
para entrar em operação, testado, treinado e suficiente.
Outro exemplo bem conhecido de um sistema redundante
em redes de computadores é o RAID (Redundant Array of
Independent Disks).
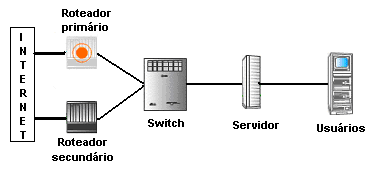
Figura 1
- Exemplo de rede redundante
No exemplo da figura
acima, com a falha do roteador primário, imediatamente
o secundário entrará em atividade de forma a manter
o funcionamento ininterrupto da comunicação da rede
local com o ambiente externo (Internet).
Outro exemplo de redund�ncia
está em m�ltiplas estações de trabalho usadas para monitorar
uma rede. A perda de uma estação não prejudica a visualização
ou a operação do sistema. Nesse caso, um servidor de
banco de dados (igualmente redundante) garante que nenhuma
informação seja perdida, na hipótese de falha do servidor
primário.
Podemos ter também a
redund�ncia física de um subsistema de alimentação de
energia, projetado para prover chaveamento automático
no caso de falha pelo acréscimo de uma segunda fonte.
Nesse subsistema redundante, as fontes possuem a mesma
capacidade e, no caso de falha de uma delas, a outra
assume instantaneamente toda a carga da rede.
Outro aspecto que deve
ser considerado é a contingência operacional proporcionada
pela redund�ncia de equipamentos. Quanto maior a vulnerabilidade
de um sistema dentro de uma rede, maior a redund�ncia
necessária para garantir a integridade dessa rede. Em
alguns casos, porém, a simples contingência representada
pela redund�ncia dos equipamentos e do processo de backup
não são suficientes para tornar o "downtime"
compatível com a necessidade operacional da empresa.
Contingência
Define-se contingência
como a possibilidade de um fato acontecer ou não. �
uma situação de risco existente, mas que envolve um
grau de incerteza quanto à sua efetiva ocorrência. As
ações de contingenciamento são encadeadas, e por vezes
sobrepostas, de acordo com procedimentos previamente
acordados no projeto da rede. O seq�enciamento das ações
depende dos acontecimentos que precederam o evento (contingência)
bem como das condições contextuais que vão sendo construídas
no próprio processo, ou seja, o processo de contingenciamento
é construído e negociado à medida que a interação se
processa.
Sucintamente, as condições
necessárias para a existência de uma contingência são:
possibilidade de um acontecimento futuro resultante
de uma condição existente, incerteza sobre as condições
operacionais envolvidas e a resolução destas condições
dependerem de eventos futuros.
Objetivos da Contingência
O projeto do contingenciamento
da rede deve estar baseado em políticas que visem alta
disponibilidade de informações e sistemas, através de
suporte técnico, sistemas de segurança, esquemas de
backup, planos de contingência, redund�ncia de equipamentos
e canais de comunicação e gerenciamento pró-ativo. O
objetivo é implantar, conectado à estrutura de rede
de computadores, um plano de acesso seguro, eficiente
e gerenciado, capaz de restabelecer as funções críticas
numa situação excepcional.
Planos de contingência
Trata-se do conjunto
de procedimentos e medidas de segurança preventivas,
previamente planejadas, a serem adotados após a ocorrência
de uma falha, que permitem o restabelecimento da rede
de comunicação em caso de situações anormais (falha
de hardware, base de dados corrompida, perda de link
de comunicação, destruição de prédios, entre outras),
com o objetivo de minimizar os impactos da mesma.
Os planos de contingência
são desenvolvidos para cada ameaça considerada em cada
um dos processos do negócio pertencentes ao escopo,
definindo em detalhes os procedimentos a serem executados
em estado de contingência. Na implementação do plano
devem ser avaliados os principais riscos que podem fazer
o sistema parar. Para isso, deve-se proceder ao levantamento
dos impactos dessa parada em cada área de negócio e
estimar quanto tempo levaria para restabelecer o processamento
para cada risco e para cada área.
Os planos de contingência
estão subdivididos em três módulos distintos e complementares
que tratam especificamente de cada momento vivido pela
empresa:
Plano de Administração
de Crise � Tem o propósito
de definir passo-a-passo o funcionamento das equipes
envolvidas com o acionamento da contingência antes,
durante e depois da ocorrência do incidente. Além
disso, tem que definir os procedimentos a serem
executados pela mesma equipe no período de retorno
à normalidade. O comportamento da empresa na comunicação
do fato à imprensa é um exemplo típico de tratamento
dado pelo plano;
Plano de Continuidade
Operacional � Tem o propósito
de definir os procedimentos para contingenciamento
dos ativos que suportam cada processo de negócio,
objetivando reduzir o tempo de indisponibilidade
e, conseq�entemente, os impactos potenciais ao negócio.
Orientar as ações diante da queda de uma conexão
à Internet, exemplificam os desafios organizados
pelo plano;
Plano de Recuperação
de Desastres � Tem o propósito
de definir um plano de recuperação e restauração
das funcionalidades dos ativos afetados que suportam
os processo de negócio, a fim de restabelecer o
ambiente e as condições originais de operação. Descreve
as medidas que uma empresa deve tomar, incluindo
a ativação de processos manuais ou o recurso a contratos,
para assegurar a continuidade dos processos do negócio
no caso de falha no sistema de informações.
Objetivos do plano de
contingência
O principal objetivo
de um plano de contingência é dar providência imediata
invocando os procedimentos de recuperação dos sistemas
corporativos, considerando o tempo de espera previsto
para restabelecimento da atividade definido pelos gestores
do sistema. Para cada sistema corporativo, hierarquicamente
definido segundo o grau de criticidade e processamento,
são previstos o tempo de paralisação possível e ações
subseq�entes para seu restabelecimento.
De forma global, as
ocorrências de falha mais comuns são: Vírus, perda de
disco rígido, perda de um servidor da rede ou de uma
ligação de rede, alteração/atualização de software,
falha de sistema de suporte (ar condicionado e/ou de
energia, por exemplo), avarias mec�nicas do hardware,
etc.
Um plano de contingência
deve se caracterizar pelos seguintes aspectos:
Ser desenvolvido
por uma equipe de trabalho que envolva todas as
áreas de conhecimento e de negócio da empresa a
qual o plano de contingência diz respeito;
Ser avaliado periodicamente;
Estar disponível
em local reservado e seguro, mas de fácil acesso
ao pessoal autorizado.
O plano de contingência
provê a avaliação de todas as funções de negócio juntamente
com a análise do ambiente de negócios em que a empresa
se insere, ganhando-se uma visão objetiva dos riscos
que ameaçam a organização. A metodologia para a implantação
de um plano de contingência consiste em seis etapas:
- Avaliação do projeto:
escopo e aplicabilidade;
- Análise de risco;
- Análise de impacto
em negócios;
- Desenvolvimento
dos planos de recuperação de desastres;
- Treinamento e teste
dos planos;
- Implementação e
manutenção.
Um exemplo de plano
de contingência para uma rede de computadores quanto
à prevenção de falhas nos sistemas de suporte, na infra-estrutura
e nos processos é exemplificado a seguir:
Sistemas de suporte
|
Tipo
de falha |
Medida |
| Falha
de sistema HVAC |
Identificar
os sistemas (elevadores, ar-condicionado,
aquecimento central, ventilação, temperatura,
etc) e avaliá-los quanto:
- �
sua conformidade com os par�metros de projeto,
observando a existência de sistemas proprietários;
- A
criticidade deste tipo de sistemas para
o funcionamento da rede;
- Definir
regras de utilização destes sistemas, de
modo a não p�r em risco o funcionamento
da empresa e a segurança dos usuários dos
sistemas.
|
Infra-estrutura
|
Tipo
de falha |
Medida |
|
Energia
elétrica |
- Prever
sistema alternativo de fornecimento de energia;
- Definir
o período de autonomia para o sistema;
- Prover
os recursos necessários para o funcionamento
do sistema alternativo durante o período de
autonomia pretendido;
- Identificar
as áreas prioritárias para o abastecimento
de energia.
|
|
Comunicações |
- Providenciar
meios alternativos de comunicação para receber
e transmitir as informações;
- Considerar
a hipótese de antecipar processamentos e/ou
reativar processos manuais;
|
|
Controle
Ambiental |
Alguns
equipamentos necessitam, para o seu correto
funcionamento, de determinadas condições de
temperatura e umidade. Prevendo uma eventual
falha nos mecanismos de controle e reposição
dessas condições, deve-se:
- Criar meios
alternativos para fornecer as condições mínimas
de funcionamento;
- Definir
períodos de funcionamento no sentido de minorar
a degradação das condições ambientais.
|
|
Sistemas
de combate a incêndios |
- Devem
ser colocados em controle manual;
- Prever
o eventual reforço de meios mec�nicos de combate
a incêndio.
|
|
Transportes |
Uma
eventual falha ao nível dos transportes pode
impossibilitar o acesso das pessoas ao seu local
de trabalho, inviabilizando o funcionamento
da organização:
- Viabilizar
formas de transporte alternativas, da própria
organização ou terceiros, desde que as falhas
de abastecimento de combustíveis não sejam
a um nível global. Neste caso, um planejamento
de contingência será ineficaz caso não existam
medidas a outro nível que garantam um abastecimento
em função das necessidades e prioridades da
sociedade em geral.
|
Processos
Uma rede de computadores
que possua um plano de contingência deve reagir a um
efeito danoso e dele se recuperar mesmo antes da causa
ter sido identificada e prevenir a ocorrência à falhas
indesejáveis e, simultaneamente, definir as medidas
e p�r em prática se essas falhas de fato vierem a ocorrer.
Equivale a afirmar que reação e recuperação devem ter
sucesso não importando se a causa foi ou não determinada.
Independentemente da
ocorrência de qualquer falha, devem ser feitas cópias
redundantes de toda a informação, incluindo dados, aplicações,
sistema operativo, SGBD e outros sistemas de gestão
em uso. Deve-se assegurar que, caso as cópias sejam
utilizadas, existirá, pelo menos, uma cópia fiel de
toda a informação no seu estado original. Deve igualmente
ter-se o cuidado de efetuar a reinicialização do sistema
passo a passo e a monitoração do correto funcionamento
de cada novo componente integrado ao sistema.
|
Tipo
de falha |
Medida |
|
Recebimento
de informação errada |
- Definir
procedimentos que viabilizem a verificação
da correção e coerência da informação recebida
antes do seu processamento.
|
|
Resultados
com erros |
- Definir
procedimentos visando a verificar a correção
da informação produzida.
|
|
Arquivos
corrompidos ou perdidos |
- Definir
procedimentos que permitam verificar a correção
e coerência dos dados e decidir pela continuação
ou interrupção do processamento.
|
|
Falha
de um processo |
- Hipótese de
desenvolver sistemas alternativos que possibilitem
a execução das funções principais do sistema;
- Prever
a necessidade de publicação de disposições
legais que permitam antecipar ou retardar
prazos e datas.
|
|
Falha
de fornecimento de produtos de consumo |
- Estimar
as necessidades e proceder à aquisição de
produtos prevendo não só eventuais falhas
no seu abastecimento, bem como um eventual
aumento do consumo na seq�ência, por exemplo,
da ativação de processos alternativos de troca
de informação.
|
|
Falha
do sistema central de processamento |
- Avaliar
a possibilidade de utilizar o recurso de um
centro alternativo (próprio ou de terceiros);
- Ativar
processos manuais.
|
|
Falha
da rede local |
- Listar
as tarefas/atividades afetadas por esta falha;
- Definir
formas alternativas de envio e recebimento
da informação, adequadas para cada situação.
|
|
Falha
dos sistemas por acessos abusivos |
- Definir
mecanismos de monitoração que permitam identificar
de imediato este tipo de ocorrências;
- Interromper
as comunicações até à reparação da falha.
|
Estratégias de Contingência
Host-site
� Recebe este nome por ser uma estratégia pronta
para entrar em operação assim que uma situação de
risco ocorrer. O tempo de operacionalização desta
estratégia está diretamente ligado ao tempo de toler�ncia
à falhas;
Warm-site
� Esta se aplica a objetos com maior toler�ncia
à paralisação, podendo se sujeitar à indisponibilidade
por mais tempo, até o retorno operacional da atividade.
Por exemplo, o serviço de e-mail dependente de uma
conexão e o processo de envio e recebimento de mensagens
é mais tolerante podendo ficar indisponível por
minutos, sem, no entanto, comprometer o serviço
ou gerar impactos significativos;
Cold-site
� Propõe uma alternativa de contingência a partir
de um ambiente com os recursos mínimos de infra-estrutura
e telecomunicações, desprovido de recursos de processamento
de dados. Portanto, aplicável à situação com toler�ncia
de indisponibilidade ainda maior;
Realocação de Operação
� Tem como objetivo desviar a atividade atingida
pelo evento que provocou a quebra de segurança,
para outro ambiente físico, equipamento ou link,
pertencentes à mesma empresa. Esta estratégia só
é possível com a existência de "folgas"
de recursos que podem ser alocados em situações
de crise. Muito comum essa estratégia pode ser entendida
pelo exemplo que se redireciona o tráfego de dados
de um roteador ou servidos com problemas para outro
que possua folga de processamento e suporte o ac�mulo
de tarefas;
Bureau de Serviços
� Considera a possibilidade de transferir a operacionalização
da atividade atingida para um ambiente terceirizado,
portanto, fora dos domínios da empresa. Por sua
própria natureza, em que requer um tempo de toler�ncia
maior em função do tempo de reativação operacional
da atividade, torna-se restrita a poucas situações.
O fato de ter suas informações manuseadas por terceiros
e em um ambiente fora de seu controle, requer atenção
na adoção de procedimentos, critérios e mecanismos
de controle que garantam condições de segurança
adequadas à relev�ncia e criticidade da atividade
contingenciada;
Acordo de Reciprocidade
� Propõe a aproximação e um acordo formal com empresas
que mantêm características físicas, tecnológicas
ou humanas semelhantes a sua, e que estejam igualmente
dispostas a possuir uma alternativa de continuidade
operacional. Estabelecem em conjunto as situações
de contingência e definem os procedimentos de compartilhamento
de recursos para alocar a atividade atingida no
ambiente da outra empresa. Desta forma, ambas obtêm
redução significativa dos investimentos;
Auto-suficiência
� Utilizada quando nenhuma outra estratégia é aplicável,
quando os impactos possíveis não são significativos
ou quando estas são inviáveis, seja financeiramente,
tecnicamente ou estrategicamente. A escolha de qualquer
uma das estratégias anteriores depende diretamente
do nível de toler�ncia que a empresa pode suportar.
Esta decisão pressupõe a orientação obtida por uma
análise de riscos e impactos que gere subsídios
para apoiar a escolha mais acertada.
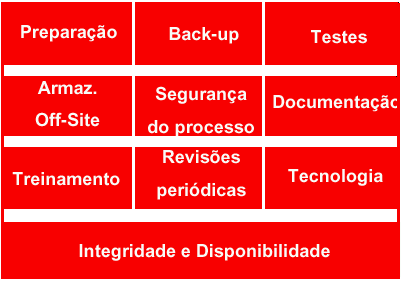
Figura 2
- Riscos envolvidos em um plano de contingência
Conclusão
A aplicação dos
conceitos de contingência e redund�ncia oferece maior
segurança e confiabilidade para a rede de computadores
através das soluções para a proteção das informações
e aplicativos, equipamentos, espaço físico e demais
funções críticas.
A redund�ncia é um fator
que pode contribuir para a disponibilidade de uma rede
de computadores. Entretanto, apenas a redund�ncia é
insuficiente, visto que um sistema pode apresentar diferentes
vulnerabilidades. Uma rede de alta disponibilidade,
por exemplo, requer que cada sistema backup ofereça
funcionalidades equivalentes, porém com implementação
diferenciada. Esta variação afasta tentativas de comprometer
tanto o sistema primário quanto o sistema de backup
a partir de uma �nica estratégia de atendimento.
Já um plano de contingência
requer procedimentos inteligíveis e objetivos, simulações
de possíveis ocorrências futuras e soluções simples,
imaginando situações possíveis, mesmo que pouco prováveis.
Induz a elaboração de procedimentos operacionais diretos
que permitam, em uma ocorrência indesejada, tomarem-se
ações que reparem ou minimizem os efeitos da falha.
As idéias são tratadas e as hipóteses classificadas
segundo a chance, o custo e a segurança envolvida.
Embora redund�ncia e
planos de contingência sobrecarreguem o funcionamento
e o gerenciamento de uma rede, ambos são necessários
para evitar problemas futuros. A decisão sobre o grau
de redund�ncia ou contingência que se deve adotar pode
ser balizada por vários fatores, entre eles: ambiente
de funcionamento da rede, protocolos e sistemas utilizados
e import�ncia da rede para o negócio da empresa.
|